Feedback Loops: From Signals to Strategy
Jul 8, 2025

The Kickoff
July’s brought more than heat. We’ve been looking at how funds respond when signals blur, how markets react more sharply to policy news, and how ideas like AI agents get tested in real hedge fund settings. Some teams are adjusting. Others are sticking to what they know. This edition is about pressure and response. Because in 2025 we've learnt that no one gets to wait for certainty.
The Compass
Here's a rundown of what you can find in this edition:
Catching you up on what’s been happening on our side
Newest partner addition to the Quanted data lake
Insights from our chat with Niall Hurley
The data behind the rising sensitivity of equities to policy and economic news
Some events this Q that will keep you informed and well socialised
How to build AI Agents for Hedge Fund Settings
Some insights we think you should hear from other established funds squinting at the signals.
Did you know this about stocks & treasury bills?
Insider Info
A bit of a reset month for us, as startup cycles go. We’ve been focused on laying the groundwork for the next phase of product and commercial growth. On the product side, we’re continuing to expand coverage, with another 1.3 million features added this month to help surface performance drivers across a wider range of market conditions.
We also kicked off a UI refresh based on early adopter feedback, aimed at making data discovery and validation easier to navigate and more intuitive for everyone using the platform.
On the community side, we joined Databento’s London events and had the chance to catch up with teams from Man, Thelasians, and Sparta. David, our Co-Founder & CTO, made his first guest appearance on the New Barbarians podcast, where he shared a bit about his background and how we’re thinking about the data problems quant teams are trying to solve.
And in case you're based in New York: our CEO has officially relocated back to the city. If you're around and up for a coffee, feel free to reach out.
More soon.
On the Radar
One new data partner to welcome this month, as we focus on getting recent additions fully onboarded and integrated into the system. Each one adds to the growing pool of features quants can test, validate, and integrate into their strategies. A warm welcome to the partner below:
Offers validated U.S. options reference data, corporate action adjustments, and intraday symbology updates to support quants running systematic strategies that depend on accurate instrument mapping, reliable security masters, and low error tolerance across research and production environments.
The Tradewinds
Expert Exchange
We recently spoke with Niall Hurley about the evolving role of data in asset management, capital markets, and corporate strategy. With 24 years of experience including sell side, buy side and the data vendor world, Niall brings a unique perspective on how data informs investment decisions and supports commercial growth.
His career includes roles in equity derivatives at Goldman Sachs and Deutsche Bank, portfolio management at RAB Capital, asset allocation at Goodbody, and M&A at Circle K Europe. He later led Eagle Alpha, one of the earliest alternative data firms, serving as CEO and Director for 7 years, where he worked closely with asset managers and data providers to shape how alternative data is sourced, evaluated, and applied. Today, Niall advises data vendors and corporates on how to assess data and create value more effectively and uncover new opportunities.
Reflecting on your journey from managing portfolios to leading an alt data company and advising data businesses, how has the role of data in investment and capital markets evolved since you started - and what’s been the most memorable turning point in your career so far?
The biggest evolution has been the growth of the availability of datasets. This has allowed data-driven insights in addition to company and economic tracking in the last 10 years that was simply not possible 20 years ago.
The most memorable turning point was learning these use cases and applications of data sources in 2017 and 2018. You cannot unlearn them! I now listen in on any conversation or exercise as it relates to deal origination, company due diligence, business or economic forecasting, completely different compared to 10 years ago. Facts beat opinions. The availability of facts, via data, has exploded.
What mindsets or workflows from your hedge fund, allocator & industry M&A roles proved most valuable when you transitioned into leading a data solution provider and advising data businesses.
The most important skills transfer was understanding companies and industries and the types of KPI’s and measurements of businesses that are required by a private or public markets analyst.
Secondary to that, it was understanding the internals of an asset manager. I covered asset managers for derivatives, worked in a multi-strategy and allocated to managers. Whenever I spend time with an asset manager, I try to consider their entire organisation, different skill sets and where the data flows from and to both in terms of central functions and decentralised strategies and teams.
Having worked on both the buy side and with data vendors, where do you see the greatest room for innovation in how firms handle data infrastructure?
It would be wrong not to mention AI. To date, generative AI and LLMs have been mainly utilised outside of production environments and away from live portfolios and trading algorithms, but that is now starting to evolve based on my recent conversations.
In many ways, nothing has changed prior to the “GPT era” - the asset management firms that continue to invest in data infrastructure, talent, and innovation are correlating with those with superior fund performance and asset growth.
Likewise, winning data vendors continue to invest in infrastructure to deliver high-quality and timely data. Their ability to add an analytics or insights layer to their raw data has declined in cost.
As alternative data becomes more embedded in investment workflows, where do you see the biggest opportunities to improve how teams extract and iterate on predictive signals at scale?
I still believe the market approaches data backtesting and evaluation data combinations to arrive at a signal is highly inefficient. When I worked in derivative markets, I saw decisions made with complex derivatives and hundreds of millions or billions of portfolio exposure in a fraction of the time it takes to alpha test a $100k dataset. Firms spend millions on sell-side research without alpha testing it. We know there is no alpha in sell-side research. There are a lot of contradictions, I guess every industry has these dynamics.
Compliance needs to be standardised and centralised; too much time is lost there. Data cleansing, wrangling, and mapping should see a structural improvement and collapse in time allocation thanks to new technologies. If we can do back testing, blending and alpha testing faster, the velocity of the ecosystem can increase in a non-linear and positive way - that is good for everyone.
Looking ahead, what kinds of data-intensive challenges are you most focused on solving now through your advisory work, whether with funds, vendors, or corporates?
Generally, it is helping funds that are focused on alpha, and winning assets on that basis, understand that if you are working with the same data types and processes in 10 years that you are working with today, your investors may allocate elsewhere. For vendors, there are a high number of sub $5mn businesses trying to work out how they can become $20mn businesses or more and brainstorming with CEOs and Founders to solve that. For companies, I still believe there is a lot of “big data” sitting in “small companies” that they have no idea of its value.
They are the main things I think about every morning – that will keep me busy for a long time, and it never feels like work helping to solve those challenges. Data markets are always changing.
Anything else you’d like to highlight for readers to keep in mind going forward?
For my Advisory work, I send out a newsletter, direct to email, for select individuals when I have something important to say. I prefer to send it directly to people I know personally from my time in the industry. For example, this month I have taken an interest in groups like Perplexity, increasing their presence with their finance offering as they secure more data access. But also, I see a real risk of many “AI” apps failing as their data inputs are not differentiated from the incumbents. We saw one of those private equity apps that support origination / due diligence exit the market this month. I see a risk that we have overallocated to “AI” apps.
Numbers & Narratives
Macro Surprise Risk Has Doubled Since 2020
BlackRock’s latest regression work draws a clear line in the sand: the post-2020 market regime exhibits double the equity sensitivity to macro and policy surprises compared to the pre-2020 baseline. Their quant team regressed weekly equity index returns on the Citi Economic Surprise Index and the Trade Policy Uncertainty Index (z-scored), and found that the aggregate regression coefficients—a proxy for short-term macro beta—have surged to 2.0, up from a long-run average closer to 1.0 between 2004 and 2019.
This implies a structural shift in the return-generating process. Short-term data surprises and geopolitical signals now exert twice the force on equity prices as they did during the last cycle. With inflation anchors unmoored and fiscal discipline fading, the equity market is effectively operating without long-duration macro gravity.
Why this matters for quants:
Signal horizon compression: Traditional models assuming slow diffusion of macro information may underreact. Short-term macro forecast accuracy is now more alpha-relevant than ever.
Conditional vol scaling: Systems using fixed beta assumptions will underprice response amplitude. Macro-news-aware vol adjustment becomes table stakes.
Feature recalibration: Pre-2020 macro-beta priors may be invalid. Factor timing models need to upweight surprise risk and regime-aware features (e.g., conditional dispersion, policy tone).
Stress path modeling: With a 2× jump in sensitivity, tail events from unanticipated data (e.g., non-farm payrolls, inflation beats) are more potent. Impact magnitudes have changed even when probabilities haven’t.
Model explainability: For machine learning-driven equity models, the sharp rise in macro sensitivity demands clearer mapping between input variables and macro regimes for interpretability.
This reflects a change in transmission mechanics rather than a simple shift in volatility. The equity market is increasingly priced like a derivative on macro surprise itself. Quants who are not tracking this evolving beta risk may find their edge structurally diluted.
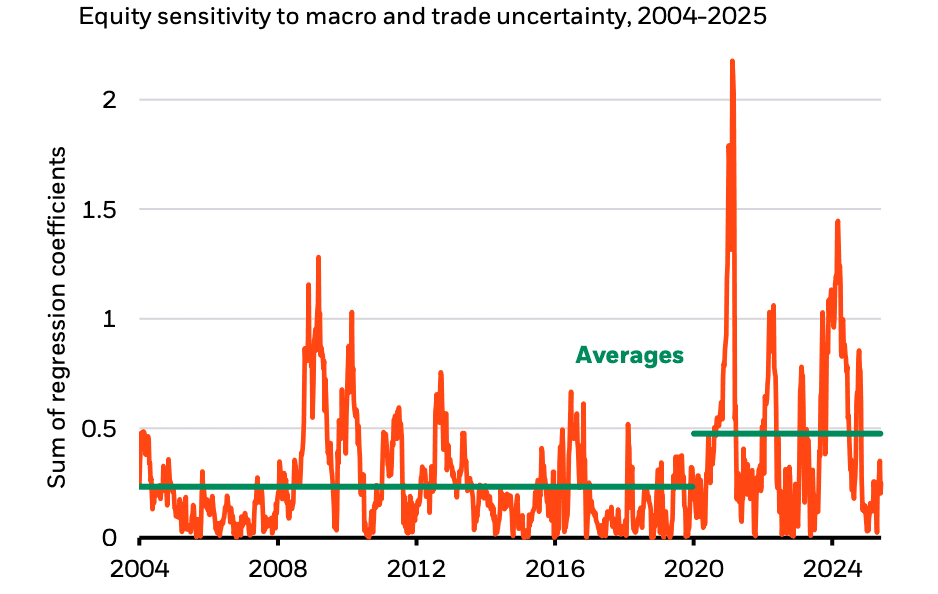
Source: Blackrock's Midyear Global Investment Outlook Report
Link to Blackrock Midyear Global Investment Outlook
Time Markers
It’s somehow already Q3 and the calendar is filling up quick. Especially later in the quarter, there’s a strong lineup of quant and data events to keep an eye on:
📆 ARPM Quant Bootcamp 2025, 7- 10 July, New York | A four-day program in New York bringing together quants, portfolio managers, and risk professionals to explore asset allocation, derivatives, and advanced quantitative methods.
📆 Eagle Alpha, 17 September, New York | A one-day event focused on how institutional investors source, evaluate, and apply alternative datasets.
📆 Data & AI Happy Hour Mixer, 17 September, New York | A chilled rooftop gathering for data and AI professionals ahead of the Databricks World Tour.
📆 Neudata, 18 September, London | A full-day event connecting data buyers and vendors to explore developments in traditional and market data.
📆 Cornell Financial Engineering 2025, 19 September, New York | A one-day conference uniting academics and practitioners to discuss AI, machine learning, and data in financial markets.
📆 Battle of the Quants, 23 September, London | A one-day event bringing together quants, allocators, and data providers to discuss AI and systematic investing.
📆 SIPUGday 2025, 23-24 September, Zurich | Two day event uniting banks, data vendors, and fintechs to discuss innovation in market data and infrastructure.
📆 Big Data LDN 2025, September 24-25, 2025, London | A two-day expo where data teams across sectors gather to explore tools and strategies in data management, analytics, and AI.
Navigational Nudges
If you’ve studied robotics, you know it teaches a harsh but valuable lesson: if a control loop is even slightly unstable, the arm slams into the workbench. Apply the same intolerance for wobble when you let a language model design trading signals. An AI agent can prototype hundreds of alphas overnight, but without hard-edged constraints it will happily learn patterns that exist only on your hard drive.
The danger isn’t that the model writes bad code. It’s that it writes seductive code. Backtests soar, Sharpe ratios gleam, and only later do you notice the subtle look-ahead, the synthetic mean-reversion baked into trade-price bars, or the hidden parameter explosion that made everything fit.
Why this matters
Quant desks already battle regime shifts and crowding. Layering a hyper-creative agent on top multiplies the ways a pipeline can hallucinate edge. Unless you engineer guard-rails as rigorously as a safety-critical robot, you swap research velocity for capital erosion.
These are the tips I’d give if you're building an AI agent that generates and tests trading signals:
Treat raw data like sensor feeds
Build OHLC bars from bid-ask mid-prices, not last trades, and store opening and closing spreads. That removes fake mean-reversion and lets you debit realistic costs.Constrain the agent’s degrees of freedom
Whitelist a compact set of inputs such as mid-price, VWAP, and basic volume. Limit it to a vetted set of transforms. No ad-hoc functions, no peeking at future books. Fewer joints mean fewer failure modes.Decouple imagination from evaluation
Stage 1: the model drafts economic hypotheses. Stage 2: a separate test harness converts formulas, charges fees, and walks a rolling train/test split. Keep the fox out of the hen-house.Penalise complexity early
Count operators or tree depth. If a feature exceeds the limit, force a rewrite. In robotics we call this weight-budgeting. Lighter parts mean fewer surprises.Track decay like component fatigue
Log every alpha, its live PnL, and break-point tests. Retire signals whose correlations slip or whose hit-rate drifts below spec. Maintenance is better than post-crash autopsy.Correct for multiple testing
Each strategy tested on the same dataset increases your chances of discovering false positives. Keep a running count of trials, apply corrections for multiple testing, and discount performance metrics accordingly. This protects your process from data mining bias and ensures that the signals you promote are statistically credible.
AI can speed up signal generation, but judgment and process determine whether those signals hold up. Treat it like you would a junior quant: give it structure, review its output, and never skip validation. The value lies not in automation itself, but in the rigour you apply when filtering ideas and deciding what makes it into production. Without that discipline, faster research just means faster failure.
The Knowledge Buffet
📝 Systematic Strategies and Quant Trading 2025 📝
by HedgeNordic
The report pulls together a series of manager writeups on how different systematic funds are adapting to today's harder-to-read markets. It's not trying to make a single argument or push a trend. Instead, you get a mix: some focus on execution and trade design, others on regime detection, signal fragility, or capacity constraints. A few make the case for sticking with simple models, others are exploring more adaptive frameworks. It's worth reading if you're interested in how different teams are handling the same pressures, without assuming there's one right answer.
The Closing Bell
Did you know?
Only 42% of U.S. stocks have outperformed one-month Treasury bills over their entire lifetime.
The Kickoff
July’s brought more than heat. We’ve been looking at how funds respond when signals blur, how markets react more sharply to policy news, and how ideas like AI agents get tested in real hedge fund settings. Some teams are adjusting. Others are sticking to what they know. This edition is about pressure and response. Because in 2025 we've learnt that no one gets to wait for certainty.
The Compass
Here's a rundown of what you can find in this edition:
Catching you up on what’s been happening on our side
Newest partner addition to the Quanted data lake
Insights from our chat with Niall Hurley
The data behind the rising sensitivity of equities to policy and economic news
Some events this Q that will keep you informed and well socialised
How to build AI Agents for Hedge Fund Settings
Some insights we think you should hear from other established funds squinting at the signals.
Did you know this about stocks & treasury bills?
Insider Info
A bit of a reset month for us, as startup cycles go. We’ve been focused on laying the groundwork for the next phase of product and commercial growth. On the product side, we’re continuing to expand coverage, with another 1.3 million features added this month to help surface performance drivers across a wider range of market conditions.
We also kicked off a UI refresh based on early adopter feedback, aimed at making data discovery and validation easier to navigate and more intuitive for everyone using the platform.
On the community side, we joined Databento’s London events and had the chance to catch up with teams from Man, Thelasians, and Sparta. David, our Co-Founder & CTO, made his first guest appearance on the New Barbarians podcast, where he shared a bit about his background and how we’re thinking about the data problems quant teams are trying to solve.
And in case you're based in New York: our CEO has officially relocated back to the city. If you're around and up for a coffee, feel free to reach out.
More soon.
On the Radar
One new data partner to welcome this month, as we focus on getting recent additions fully onboarded and integrated into the system. Each one adds to the growing pool of features quants can test, validate, and integrate into their strategies. A warm welcome to the partner below:
Offers validated U.S. options reference data, corporate action adjustments, and intraday symbology updates to support quants running systematic strategies that depend on accurate instrument mapping, reliable security masters, and low error tolerance across research and production environments.
The Tradewinds
Expert Exchange
We recently spoke with Niall Hurley about the evolving role of data in asset management, capital markets, and corporate strategy. With 24 years of experience including sell side, buy side and the data vendor world, Niall brings a unique perspective on how data informs investment decisions and supports commercial growth.
His career includes roles in equity derivatives at Goldman Sachs and Deutsche Bank, portfolio management at RAB Capital, asset allocation at Goodbody, and M&A at Circle K Europe. He later led Eagle Alpha, one of the earliest alternative data firms, serving as CEO and Director for 7 years, where he worked closely with asset managers and data providers to shape how alternative data is sourced, evaluated, and applied. Today, Niall advises data vendors and corporates on how to assess data and create value more effectively and uncover new opportunities.
Reflecting on your journey from managing portfolios to leading an alt data company and advising data businesses, how has the role of data in investment and capital markets evolved since you started - and what’s been the most memorable turning point in your career so far?
The biggest evolution has been the growth of the availability of datasets. This has allowed data-driven insights in addition to company and economic tracking in the last 10 years that was simply not possible 20 years ago.
The most memorable turning point was learning these use cases and applications of data sources in 2017 and 2018. You cannot unlearn them! I now listen in on any conversation or exercise as it relates to deal origination, company due diligence, business or economic forecasting, completely different compared to 10 years ago. Facts beat opinions. The availability of facts, via data, has exploded.
What mindsets or workflows from your hedge fund, allocator & industry M&A roles proved most valuable when you transitioned into leading a data solution provider and advising data businesses.
The most important skills transfer was understanding companies and industries and the types of KPI’s and measurements of businesses that are required by a private or public markets analyst.
Secondary to that, it was understanding the internals of an asset manager. I covered asset managers for derivatives, worked in a multi-strategy and allocated to managers. Whenever I spend time with an asset manager, I try to consider their entire organisation, different skill sets and where the data flows from and to both in terms of central functions and decentralised strategies and teams.
Having worked on both the buy side and with data vendors, where do you see the greatest room for innovation in how firms handle data infrastructure?
It would be wrong not to mention AI. To date, generative AI and LLMs have been mainly utilised outside of production environments and away from live portfolios and trading algorithms, but that is now starting to evolve based on my recent conversations.
In many ways, nothing has changed prior to the “GPT era” - the asset management firms that continue to invest in data infrastructure, talent, and innovation are correlating with those with superior fund performance and asset growth.
Likewise, winning data vendors continue to invest in infrastructure to deliver high-quality and timely data. Their ability to add an analytics or insights layer to their raw data has declined in cost.
As alternative data becomes more embedded in investment workflows, where do you see the biggest opportunities to improve how teams extract and iterate on predictive signals at scale?
I still believe the market approaches data backtesting and evaluation data combinations to arrive at a signal is highly inefficient. When I worked in derivative markets, I saw decisions made with complex derivatives and hundreds of millions or billions of portfolio exposure in a fraction of the time it takes to alpha test a $100k dataset. Firms spend millions on sell-side research without alpha testing it. We know there is no alpha in sell-side research. There are a lot of contradictions, I guess every industry has these dynamics.
Compliance needs to be standardised and centralised; too much time is lost there. Data cleansing, wrangling, and mapping should see a structural improvement and collapse in time allocation thanks to new technologies. If we can do back testing, blending and alpha testing faster, the velocity of the ecosystem can increase in a non-linear and positive way - that is good for everyone.
Looking ahead, what kinds of data-intensive challenges are you most focused on solving now through your advisory work, whether with funds, vendors, or corporates?
Generally, it is helping funds that are focused on alpha, and winning assets on that basis, understand that if you are working with the same data types and processes in 10 years that you are working with today, your investors may allocate elsewhere. For vendors, there are a high number of sub $5mn businesses trying to work out how they can become $20mn businesses or more and brainstorming with CEOs and Founders to solve that. For companies, I still believe there is a lot of “big data” sitting in “small companies” that they have no idea of its value.
They are the main things I think about every morning – that will keep me busy for a long time, and it never feels like work helping to solve those challenges. Data markets are always changing.
Anything else you’d like to highlight for readers to keep in mind going forward?
For my Advisory work, I send out a newsletter, direct to email, for select individuals when I have something important to say. I prefer to send it directly to people I know personally from my time in the industry. For example, this month I have taken an interest in groups like Perplexity, increasing their presence with their finance offering as they secure more data access. But also, I see a real risk of many “AI” apps failing as their data inputs are not differentiated from the incumbents. We saw one of those private equity apps that support origination / due diligence exit the market this month. I see a risk that we have overallocated to “AI” apps.
Numbers & Narratives
Macro Surprise Risk Has Doubled Since 2020
BlackRock’s latest regression work draws a clear line in the sand: the post-2020 market regime exhibits double the equity sensitivity to macro and policy surprises compared to the pre-2020 baseline. Their quant team regressed weekly equity index returns on the Citi Economic Surprise Index and the Trade Policy Uncertainty Index (z-scored), and found that the aggregate regression coefficients—a proxy for short-term macro beta—have surged to 2.0, up from a long-run average closer to 1.0 between 2004 and 2019.
This implies a structural shift in the return-generating process. Short-term data surprises and geopolitical signals now exert twice the force on equity prices as they did during the last cycle. With inflation anchors unmoored and fiscal discipline fading, the equity market is effectively operating without long-duration macro gravity.
Why this matters for quants:
Signal horizon compression: Traditional models assuming slow diffusion of macro information may underreact. Short-term macro forecast accuracy is now more alpha-relevant than ever.
Conditional vol scaling: Systems using fixed beta assumptions will underprice response amplitude. Macro-news-aware vol adjustment becomes table stakes.
Feature recalibration: Pre-2020 macro-beta priors may be invalid. Factor timing models need to upweight surprise risk and regime-aware features (e.g., conditional dispersion, policy tone).
Stress path modeling: With a 2× jump in sensitivity, tail events from unanticipated data (e.g., non-farm payrolls, inflation beats) are more potent. Impact magnitudes have changed even when probabilities haven’t.
Model explainability: For machine learning-driven equity models, the sharp rise in macro sensitivity demands clearer mapping between input variables and macro regimes for interpretability.
This reflects a change in transmission mechanics rather than a simple shift in volatility. The equity market is increasingly priced like a derivative on macro surprise itself. Quants who are not tracking this evolving beta risk may find their edge structurally diluted.
Source: Blackrock's Midyear Global Investment Outlook Report
Link to Blackrock Midyear Global Investment Outlook
Time Markers
It’s somehow already Q3 and the calendar is filling up quick. Especially later in the quarter, there’s a strong lineup of quant and data events to keep an eye on:
📆 ARPM Quant Bootcamp 2025, 7- 10 July, New York | A four-day program in New York bringing together quants, portfolio managers, and risk professionals to explore asset allocation, derivatives, and advanced quantitative methods.
📆 Eagle Alpha, 17 September, New York | A one-day event focused on how institutional investors source, evaluate, and apply alternative datasets.
📆 Data & AI Happy Hour Mixer, 17 September, New York | A chilled rooftop gathering for data and AI professionals ahead of the Databricks World Tour.
📆 Neudata, 18 September, London | A full-day event connecting data buyers and vendors to explore developments in traditional and market data.
📆 Cornell Financial Engineering 2025, 19 September, New York | A one-day conference uniting academics and practitioners to discuss AI, machine learning, and data in financial markets.
📆 Battle of the Quants, 23 September, London | A one-day event bringing together quants, allocators, and data providers to discuss AI and systematic investing.
📆 SIPUGday 2025, 23-24 September, Zurich | Two day event uniting banks, data vendors, and fintechs to discuss innovation in market data and infrastructure.
📆 Big Data LDN 2025, September 24-25, 2025, London | A two-day expo where data teams across sectors gather to explore tools and strategies in data management, analytics, and AI.
Navigational Nudges
If you’ve studied robotics, you know it teaches a harsh but valuable lesson: if a control loop is even slightly unstable, the arm slams into the workbench. Apply the same intolerance for wobble when you let a language model design trading signals. An AI agent can prototype hundreds of alphas overnight, but without hard-edged constraints it will happily learn patterns that exist only on your hard drive.
The danger isn’t that the model writes bad code. It’s that it writes seductive code. Backtests soar, Sharpe ratios gleam, and only later do you notice the subtle look-ahead, the synthetic mean-reversion baked into trade-price bars, or the hidden parameter explosion that made everything fit.
Why this matters
Quant desks already battle regime shifts and crowding. Layering a hyper-creative agent on top multiplies the ways a pipeline can hallucinate edge. Unless you engineer guard-rails as rigorously as a safety-critical robot, you swap research velocity for capital erosion.
These are the tips I’d give if you're building an AI agent that generates and tests trading signals:
Treat raw data like sensor feeds
Build OHLC bars from bid-ask mid-prices, not last trades, and store opening and closing spreads. That removes fake mean-reversion and lets you debit realistic costs.Constrain the agent’s degrees of freedom
Whitelist a compact set of inputs such as mid-price, VWAP, and basic volume. Limit it to a vetted set of transforms. No ad-hoc functions, no peeking at future books. Fewer joints mean fewer failure modes.Decouple imagination from evaluation
Stage 1: the model drafts economic hypotheses. Stage 2: a separate test harness converts formulas, charges fees, and walks a rolling train/test split. Keep the fox out of the hen-house.Penalise complexity early
Count operators or tree depth. If a feature exceeds the limit, force a rewrite. In robotics we call this weight-budgeting. Lighter parts mean fewer surprises.Track decay like component fatigue
Log every alpha, its live PnL, and break-point tests. Retire signals whose correlations slip or whose hit-rate drifts below spec. Maintenance is better than post-crash autopsy.Correct for multiple testing
Each strategy tested on the same dataset increases your chances of discovering false positives. Keep a running count of trials, apply corrections for multiple testing, and discount performance metrics accordingly. This protects your process from data mining bias and ensures that the signals you promote are statistically credible.
AI can speed up signal generation, but judgment and process determine whether those signals hold up. Treat it like you would a junior quant: give it structure, review its output, and never skip validation. The value lies not in automation itself, but in the rigour you apply when filtering ideas and deciding what makes it into production. Without that discipline, faster research just means faster failure.
The Knowledge Buffet
📝 Systematic Strategies and Quant Trading 2025 📝
by HedgeNordic
The report pulls together a series of manager writeups on how different systematic funds are adapting to today's harder-to-read markets. It's not trying to make a single argument or push a trend. Instead, you get a mix: some focus on execution and trade design, others on regime detection, signal fragility, or capacity constraints. A few make the case for sticking with simple models, others are exploring more adaptive frameworks. It's worth reading if you're interested in how different teams are handling the same pressures, without assuming there's one right answer.
The Closing Bell
Did you know?
Only 42% of U.S. stocks have outperformed one-month Treasury bills over their entire lifetime.
The Kickoff
July’s brought more than heat. We’ve been looking at how funds respond when signals blur, how markets react more sharply to policy news, and how ideas like AI agents get tested in real hedge fund settings. Some teams are adjusting. Others are sticking to what they know. This edition is about pressure and response. Because in 2025 we've learnt that no one gets to wait for certainty.
The Compass
Here's a rundown of what you can find in this edition:
Catching you up on what’s been happening on our side
Newest partner addition to the Quanted data lake
Insights from our chat with Niall Hurley
The data behind the rising sensitivity of equities to policy and economic news
Some events this Q that will keep you informed and well socialised
How to build AI Agents for Hedge Fund Settings
Some insights we think you should hear from other established funds squinting at the signals.
Did you know this about stocks & treasury bills?
Insider Info
A bit of a reset month for us, as startup cycles go. We’ve been focused on laying the groundwork for the next phase of product and commercial growth. On the product side, we’re continuing to expand coverage, with another 1.3 million features added this month to help surface performance drivers across a wider range of market conditions.
We also kicked off a UI refresh based on early adopter feedback, aimed at making data discovery and validation easier to navigate and more intuitive for everyone using the platform.
On the community side, we joined Databento’s London events and had the chance to catch up with teams from Man, Thelasians, and Sparta. David, our Co-Founder & CTO, made his first guest appearance on the New Barbarians podcast, where he shared a bit about his background and how we’re thinking about the data problems quant teams are trying to solve.
And in case you're based in New York: our CEO has officially relocated back to the city. If you're around and up for a coffee, feel free to reach out.
More soon.
On the Radar
One new data partner to welcome this month, as we focus on getting recent additions fully onboarded and integrated into the system. Each one adds to the growing pool of features quants can test, validate, and integrate into their strategies. A warm welcome to the partner below:
Offers validated U.S. options reference data, corporate action adjustments, and intraday symbology updates to support quants running systematic strategies that depend on accurate instrument mapping, reliable security masters, and low error tolerance across research and production environments.
The Tradewinds
Expert Exchange
We recently spoke with Niall Hurley about the evolving role of data in asset management, capital markets, and corporate strategy. With 24 years of experience including sell side, buy side and the data vendor world, Niall brings a unique perspective on how data informs investment decisions and supports commercial growth.
His career includes roles in equity derivatives at Goldman Sachs and Deutsche Bank, portfolio management at RAB Capital, asset allocation at Goodbody, and M&A at Circle K Europe. He later led Eagle Alpha, one of the earliest alternative data firms, serving as CEO and Director for 7 years, where he worked closely with asset managers and data providers to shape how alternative data is sourced, evaluated, and applied. Today, Niall advises data vendors and corporates on how to assess data and create value more effectively and uncover new opportunities.
Reflecting on your journey from managing portfolios to leading an alt data company and advising data businesses, how has the role of data in investment and capital markets evolved since you started - and what’s been the most memorable turning point in your career so far?
The biggest evolution has been the growth of the availability of datasets. This has allowed data-driven insights in addition to company and economic tracking in the last 10 years that was simply not possible 20 years ago.
The most memorable turning point was learning these use cases and applications of data sources in 2017 and 2018. You cannot unlearn them! I now listen in on any conversation or exercise as it relates to deal origination, company due diligence, business or economic forecasting, completely different compared to 10 years ago. Facts beat opinions. The availability of facts, via data, has exploded.
What mindsets or workflows from your hedge fund, allocator & industry M&A roles proved most valuable when you transitioned into leading a data solution provider and advising data businesses.
The most important skills transfer was understanding companies and industries and the types of KPI’s and measurements of businesses that are required by a private or public markets analyst.
Secondary to that, it was understanding the internals of an asset manager. I covered asset managers for derivatives, worked in a multi-strategy and allocated to managers. Whenever I spend time with an asset manager, I try to consider their entire organisation, different skill sets and where the data flows from and to both in terms of central functions and decentralised strategies and teams.
Having worked on both the buy side and with data vendors, where do you see the greatest room for innovation in how firms handle data infrastructure?
It would be wrong not to mention AI. To date, generative AI and LLMs have been mainly utilised outside of production environments and away from live portfolios and trading algorithms, but that is now starting to evolve based on my recent conversations.
In many ways, nothing has changed prior to the “GPT era” - the asset management firms that continue to invest in data infrastructure, talent, and innovation are correlating with those with superior fund performance and asset growth.
Likewise, winning data vendors continue to invest in infrastructure to deliver high-quality and timely data. Their ability to add an analytics or insights layer to their raw data has declined in cost.
As alternative data becomes more embedded in investment workflows, where do you see the biggest opportunities to improve how teams extract and iterate on predictive signals at scale?
I still believe the market approaches data backtesting and evaluation data combinations to arrive at a signal is highly inefficient. When I worked in derivative markets, I saw decisions made with complex derivatives and hundreds of millions or billions of portfolio exposure in a fraction of the time it takes to alpha test a $100k dataset. Firms spend millions on sell-side research without alpha testing it. We know there is no alpha in sell-side research. There are a lot of contradictions, I guess every industry has these dynamics.
Compliance needs to be standardised and centralised; too much time is lost there. Data cleansing, wrangling, and mapping should see a structural improvement and collapse in time allocation thanks to new technologies. If we can do back testing, blending and alpha testing faster, the velocity of the ecosystem can increase in a non-linear and positive way - that is good for everyone.
Looking ahead, what kinds of data-intensive challenges are you most focused on solving now through your advisory work, whether with funds, vendors, or corporates?
Generally, it is helping funds that are focused on alpha, and winning assets on that basis, understand that if you are working with the same data types and processes in 10 years that you are working with today, your investors may allocate elsewhere. For vendors, there are a high number of sub $5mn businesses trying to work out how they can become $20mn businesses or more and brainstorming with CEOs and Founders to solve that. For companies, I still believe there is a lot of “big data” sitting in “small companies” that they have no idea of its value.
They are the main things I think about every morning – that will keep me busy for a long time, and it never feels like work helping to solve those challenges. Data markets are always changing.
Anything else you’d like to highlight for readers to keep in mind going forward?
For my Advisory work, I send out a newsletter, direct to email, for select individuals when I have something important to say. I prefer to send it directly to people I know personally from my time in the industry. For example, this month I have taken an interest in groups like Perplexity, increasing their presence with their finance offering as they secure more data access. But also, I see a real risk of many “AI” apps failing as their data inputs are not differentiated from the incumbents. We saw one of those private equity apps that support origination / due diligence exit the market this month. I see a risk that we have overallocated to “AI” apps.
Numbers & Narratives
Macro Surprise Risk Has Doubled Since 2020
BlackRock’s latest regression work draws a clear line in the sand: the post-2020 market regime exhibits double the equity sensitivity to macro and policy surprises compared to the pre-2020 baseline. Their quant team regressed weekly equity index returns on the Citi Economic Surprise Index and the Trade Policy Uncertainty Index (z-scored), and found that the aggregate regression coefficients—a proxy for short-term macro beta—have surged to 2.0, up from a long-run average closer to 1.0 between 2004 and 2019.
This implies a structural shift in the return-generating process. Short-term data surprises and geopolitical signals now exert twice the force on equity prices as they did during the last cycle. With inflation anchors unmoored and fiscal discipline fading, the equity market is effectively operating without long-duration macro gravity.
Why this matters for quants:
Signal horizon compression: Traditional models assuming slow diffusion of macro information may underreact. Short-term macro forecast accuracy is now more alpha-relevant than ever.
Conditional vol scaling: Systems using fixed beta assumptions will underprice response amplitude. Macro-news-aware vol adjustment becomes table stakes.
Feature recalibration: Pre-2020 macro-beta priors may be invalid. Factor timing models need to upweight surprise risk and regime-aware features (e.g., conditional dispersion, policy tone).
Stress path modeling: With a 2× jump in sensitivity, tail events from unanticipated data (e.g., non-farm payrolls, inflation beats) are more potent. Impact magnitudes have changed even when probabilities haven’t.
Model explainability: For machine learning-driven equity models, the sharp rise in macro sensitivity demands clearer mapping between input variables and macro regimes for interpretability.
This reflects a change in transmission mechanics rather than a simple shift in volatility. The equity market is increasingly priced like a derivative on macro surprise itself. Quants who are not tracking this evolving beta risk may find their edge structurally diluted.
Source: Blackrock's Midyear Global Investment Outlook Report
Link to Blackrock Midyear Global Investment Outlook
Time Markers
It’s somehow already Q3 and the calendar is filling up quick. Especially later in the quarter, there’s a strong lineup of quant and data events to keep an eye on:
📆 ARPM Quant Bootcamp 2025, 7- 10 July, New York | A four-day program in New York bringing together quants, portfolio managers, and risk professionals to explore asset allocation, derivatives, and advanced quantitative methods.
📆 Eagle Alpha, 17 September, New York | A one-day event focused on how institutional investors source, evaluate, and apply alternative datasets.
📆 Data & AI Happy Hour Mixer, 17 September, New York | A chilled rooftop gathering for data and AI professionals ahead of the Databricks World Tour.
📆 Neudata, 18 September, London | A full-day event connecting data buyers and vendors to explore developments in traditional and market data.
📆 Cornell Financial Engineering 2025, 19 September, New York | A one-day conference uniting academics and practitioners to discuss AI, machine learning, and data in financial markets.
📆 Battle of the Quants, 23 September, London | A one-day event bringing together quants, allocators, and data providers to discuss AI and systematic investing.
📆 SIPUGday 2025, 23-24 September, Zurich | Two day event uniting banks, data vendors, and fintechs to discuss innovation in market data and infrastructure.
📆 Big Data LDN 2025, September 24-25, 2025, London | A two-day expo where data teams across sectors gather to explore tools and strategies in data management, analytics, and AI.
Navigational Nudges
If you’ve studied robotics, you know it teaches a harsh but valuable lesson: if a control loop is even slightly unstable, the arm slams into the workbench. Apply the same intolerance for wobble when you let a language model design trading signals. An AI agent can prototype hundreds of alphas overnight, but without hard-edged constraints it will happily learn patterns that exist only on your hard drive.
The danger isn’t that the model writes bad code. It’s that it writes seductive code. Backtests soar, Sharpe ratios gleam, and only later do you notice the subtle look-ahead, the synthetic mean-reversion baked into trade-price bars, or the hidden parameter explosion that made everything fit.
Why this matters
Quant desks already battle regime shifts and crowding. Layering a hyper-creative agent on top multiplies the ways a pipeline can hallucinate edge. Unless you engineer guard-rails as rigorously as a safety-critical robot, you swap research velocity for capital erosion.
These are the tips I’d give if you're building an AI agent that generates and tests trading signals:
Treat raw data like sensor feeds
Build OHLC bars from bid-ask mid-prices, not last trades, and store opening and closing spreads. That removes fake mean-reversion and lets you debit realistic costs.Constrain the agent’s degrees of freedom
Whitelist a compact set of inputs such as mid-price, VWAP, and basic volume. Limit it to a vetted set of transforms. No ad-hoc functions, no peeking at future books. Fewer joints mean fewer failure modes.Decouple imagination from evaluation
Stage 1: the model drafts economic hypotheses. Stage 2: a separate test harness converts formulas, charges fees, and walks a rolling train/test split. Keep the fox out of the hen-house.Penalise complexity early
Count operators or tree depth. If a feature exceeds the limit, force a rewrite. In robotics we call this weight-budgeting. Lighter parts mean fewer surprises.Track decay like component fatigue
Log every alpha, its live PnL, and break-point tests. Retire signals whose correlations slip or whose hit-rate drifts below spec. Maintenance is better than post-crash autopsy.Correct for multiple testing
Each strategy tested on the same dataset increases your chances of discovering false positives. Keep a running count of trials, apply corrections for multiple testing, and discount performance metrics accordingly. This protects your process from data mining bias and ensures that the signals you promote are statistically credible.
AI can speed up signal generation, but judgment and process determine whether those signals hold up. Treat it like you would a junior quant: give it structure, review its output, and never skip validation. The value lies not in automation itself, but in the rigour you apply when filtering ideas and deciding what makes it into production. Without that discipline, faster research just means faster failure.
The Knowledge Buffet
📝 Systematic Strategies and Quant Trading 2025 📝
by HedgeNordic
The report pulls together a series of manager writeups on how different systematic funds are adapting to today's harder-to-read markets. It's not trying to make a single argument or push a trend. Instead, you get a mix: some focus on execution and trade design, others on regime detection, signal fragility, or capacity constraints. A few make the case for sticking with simple models, others are exploring more adaptive frameworks. It's worth reading if you're interested in how different teams are handling the same pressures, without assuming there's one right answer.
The Closing Bell
Did you know?
Only 42% of U.S. stocks have outperformed one-month Treasury bills over their entire lifetime.



