The Kickoff
June’s here, and with it, a reminder that recovery isn’t always linear, whether you’re talking models, markets, or mindset. We’ve been spending time in the in-betweens: between regimes, between theory and practice, between what the data says and what it means. Not everything resolves neatly. But that’s often where the best questions live.
The Compass
Here's a rundown of what you can find in this edition:
Some updates for anyone wondering what we’ve been up to.
What we learned from our chat with Fred Viole, founder of OVVO Labs
What the data says about US stock drawdowns and recovery odds
What we’re watching in the markets right now
The do’s and don’ts of choosing a time-series CV method
Some insights we think you should hear from Mark Fleming-Williams on data sourcing.
Your daily dose of humour - because you deserve it.
Insider Info
Milestone month across funding, product, and team this month. Our most recent fundraise is now officially out in the wild with coverage from Tech.eu. The round is a foundational step in backing the technical buildout needed to bring faster, more robust data validation to quant finance.
That said, on the product side, we’ve now surpassed 3.2 million features in our system. We’ve also spent most of our month refining our product which now has:
introduced aggregated reports that summarise results across multiple tests, helping users make quicker and more confident dataset decisions.
added features that capture clustered signals describing current market states, giving users more context around model performance.
expanded user controls, letting quants customise filters and preferences to surface data that aligns with their strategy or domain focus.
As part of our ongoing effort to give young talent a tangible entry point into quantitative finance, we welcomed Alperen Öztürk this month as our new product intern. Our product internships offer hands-on experience and the chance to work closely with our CTO and senior team.
We’re also actively growing the team. Roles across data science, full stack development, product, and GTM frequently pop up, so keep an eye on our job ads page if you or someone in your network is exploring new opportunities. Plenty more in the works :)
On the Radar
We've welcomed many new data partners this month, each enriching the pool of features quants have at their fingertips. All ready to unpack, test, and integrate into their strategies. A warm welcome to the partners below:
Context Analytics
Provides structured, machine-readable data from social media, corporate filings, and earnings call transcripts, enabling quants to integrate real-time sentiment and thematic signals into predictive models for alpha generation and risk assessment.
Paragon Intel
Provides analytics on 2,000 company c-suites, linking executive ability to with future company performance. Leverages proprietary interviews with former colleagues, predictive ratings, and AI analysis of earnings call Q&A to produce consistent, predictive signal.
The Tradewinds
Expert Exchange
We recently sat down with Fred Viole, Founder of OVVO Labs and creator of the NNS statistical framework, to explore his nonlinear approach to quantitative finance. With a career spanning decades as a trader, researcher, and portfolio manager- including time at Morgan Stanley and TGAM - Fred brings a distinctive perspective that bridges behavioural finance, numerical analysis, and machine learning.
Fred is also the co-author of Nonlinear Nonparametric Statistics and Physics Envy, two works that rethink risk and utility through a more flexible and data-driven lens. Alongside his research, he has developed open-source tools like the NNS and meboot R packages, which allow quants to model uncertainty and asymmetry without relying on restrictive assumptions. These methods now power a range of applications, from macro forecasting to option pricing and portfolio optimisation.
In our conversation, Fred shares the ideas behind partial moments, the need to move beyond symmetric risk metrics, and how OVVO Labs is translating nonlinear statistics into real-world applications for quants and investors alike.
You’ve traded markets since the 1990s. What’s the biggest change you’ve noticed in how quants approach statistical modeling and risk since then?
My passion for markets started early, shaped by my father’s NYSE seat and our Augusts spent at Monmouth Park and Saratoga racetracks, watching his horses run while learning probability through betting and absorbing trading anecdotes. By the time I left Morgan Stanley in 1999 to run a day trading office, handling 20% of daily volume in stocks like INFY, SDLI, and NTAP with sub-minute holds felt like high-frequency trading, until decimalization drove us into sub-second rebate trading.
The biggest shift in quantitative finance since then has been the relentless push to ultra-high frequencies, where technological edge, latency arbitrage, co-location, and fast execution often overshadows statistical modeling. While high-frequency trading leans on infrastructure, longer-term stat-arb has pivoted from classical statistical methods, which struggle with tail risks and nonlinearities, to machine learning (ML) techniques that promise to capture complex market dynamics.
But ML’s sophistication masks a paradox. While it detects nonlinear patterns, its foundations of covariance matrices and correlation assumptions are inherited from classical statistics. My work with partial moments addresses this: tools like CLPM (Co-Lower Partial Moments) and CUPM (Co-Upper Partial Moments) quantify how assets move together in crashes and rallies separately, without assuming linearity or normality. ML’s black-box models, by contrast, often obscure these dynamics, risking overfitting or missing tail events, a flaw reminiscent of 2008’s models, which collapsed under the weight of their own assumptions.
The result? My framework bridges ML’s flexibility with classical rigor. By replacing correlation matrices with nonparametric partial moments, we gain robustness, nonlinear insights and interpretability, like upgrading from a blurry satellite image to a high-resolution MRI of market risks.
What single skill or mindset shift made the most difference when transitioning successfully from discretionary trading to fully automated systems?
In the early 2000s, trading spot FX with grueling hours pushed me to automate my process. The pivotal mindset shift came from embracing Mandelbrot’s fractals and self-similarity, realizing all time frames were equally valid for trading setups. By mathematically modeling my discretionary approach, I built a system trading FX, commodities, and equities, netting positions across independently traded time frames. This produced asymmetric, positively skewed returns, often wrong on small exposures (one contract or 100 shares) but highly profitable when all time frames aligned with full allocations, a dynamic I later captured with partial moments in my NNS R package.
This shift solved my position sizing problem, which I prioritize above exits and then entries, and codified adding to winning positions, a key trading edge. It required abandoning my fixation on high win rates, accepting frequent small losses for outsized gains, a principle later reflected in my upper partial moment (UPM) to lower partial moment (LPM) ratio.
Can you walk us through the moment you first realised variance wasn’t telling
the full story, and how that led you to partial moments?
In the late 2000s, a hiring manager at a quant fund told me my trading system’s Sharpe ratio was too low, despite its highly asymmetrical risk-reward profile and positively skewed returns. Frustrated, I consulted my professor, who pointed me to David Nawrocki, and during our first meeting, he sketched partial moment formulas on a blackboard (a true a-ha moment for me!). It clicked that variance treated gains and losses symmetrically, double-counting observations as both risk and reward in most performance metrics, which misaligned with my trading intuition from years at Morgan Stanley and running a day trading office. This led me to develop the upper partial moment (UPM) to lower partial moment (LPM) ratio as a Sharpe replacement, capturing upside potential and downside risk separately in a nonparametric way.
The enthusiasm for the UPM/LPM ratio spurred years of research into utility theory to provide a theoretical backbone, resulting in several published papers on a full partial moments utility function. Any and all evaluation of returns inherently maps to a utility function, an inconvenient truth for many quants. I reached out to Harry Markowitz, whose early utility work resonated with my portfolio goals, sparking a multi-year correspondence. He endorsed my framework, writing letters of recommendation and acknowledging that my partial moments approach constitutes a general portfolio theory, with mean-variance as a subset.
This work, leveraging the partitioning of variance and covariance, eventually refactored traditional statistical tools (pretty much anything with a σ in it) into their partial moments equivalents, leading to the NNS (Nonlinear Nonparametric Statistics) R package. Today, NNS lets quants replace assumptions-heavy models with flexible, asymmetry-aware tools, a direct outcome of that initial frustration with variance’s blind spots.
How is the wider adoption of nonlinear statistical modelling changing the way
quants design strategies, test robustness, and iterate on their models as market conditions evolve?
Nonlinear statistical modeling, like my partial moments framework, is transforming quant strategies by prioritizing the asymmetry between gains and losses, moving beyond linear correlations and Gaussian assumptions to capture complex market dynamics. Despite this progress, many quants still rely on theoretically flawed shortcuts like CVaR, which Harry Markowitz rejected for assuming a linear utility function for losses beyond a threshold, contradicting decades of behavioral finance research. My NNS package addresses this with non- parametric partial moment matrices (CLPM, CUPM, DLPM, DUPM), which reveal nonlinear co-movements missed by traditional metrics. For instance, my stress-testing method isolates CLPM quadrants to preserve dependence structures in extreme scenarios, outperforming standard Monte Carlo simulations.
Robustness testing has evolved significantly with my Maximum Entropy Bootstrap, originally inspired by my co-author Hrishikesh Vinod, who worked under Tukey at Bell Labs and encouraged me to program NNS in R. This bootstrap generates synthetic data with controlled correlations and dependencies, ensuring strategies hold up across diverse market conditions. If your data is nonstationary and complex (e.g., financial time series with regime shifts), empirical distribution assumptions are typically preferred because they prioritize flexibility and fidelity to the data’s true behavior.
As market structure evolves, where do you think nonlinear tools will add the
most value over the next decade?
Over the next decade, nonlinear tools like partial moments will add the most value in personalized portfolio management and real-time risk assessment. As markets become more fragmented with alternative assets and high-frequency data, traditional models struggle to capture nonlinear dependencies and tail risks. My partial moment framework, embedded in tools like the OVVO Labs portfolio tool, allows investors to customize portfolios by specifying risk profiles (e.g., loss aversion to risk-seeking), directly integrating utility preferences into covariance matrices. This is critical as retail and institutional investors demand strategies tailored to their unique risk tolerances, especially in volatile environments. Not everyone should have the same portfolio!
Additionally, nonlinear tools will shine in stress testing and macro forecasting. My stress-testing approach and my MacroNow tool demonstrate how nonparametric methods can model extreme scenarios and predict macroeconomic variables (e.g., GDP, CPI) with high accuracy. As market structures incorporate AI-driven trading and complex derivatives, nonlinear tools will provide the flexibility to adapt to new data regimes, ensuring quants can manage risks and seize opportunities in real time.
What is the next major project or initiative you’re working on at OVVO Labs, and how do you see it improving the quant domain?
At OVVO Labs, my next major initiative is to integrate a more conversational interface for the end user, while also offering more customization and API access for more experienced quants. This platform will lever- age partial moments to offer quants and retail investors a seamless way to construct utility-driven strategies, stress-test portfolios, and forecast economic indicators, all while incorporating nonlinear dependence measures and dynamic regression techniques from NNS.
This project will improve the quant domain by democratizing advanced nonlinear tools, making them as intuitive as mean-variance models but far more robust. By bridging R and Python ecosystems and enhancing our GPT tool, we’ll empower quants to rapidly prototype and deploy strategies that adapt to market shifts, from high-frequency trading to long-term asset allocation. The goal is to move the industry toward empirical, utility-centric modeling, reducing reliance on outdated assumptions and enabling better decision-making in complex markets.
Anything else you'd like to highlight for those looking to deepen their statistical toolkit?
I’m excited to promote the NNS R package, a game-changer for statistical analysis across finance, economics, and beyond. These robust statistics provide the basis for nonlinear analysis while retaining linear equivalences. NNS offers: Numerical integration, Numerical differentiation, Clustering, Correlation, Dependence, Causal analysis, ANOVA, Regression, Classification, Seasonality, Autoregressive modeling, Normalization, Stochastic dominance and Advanced Monte Carlo sampling, covering roughly 90% of applied statistics. Its open-source nature on GitHub makes it accessible for quants, researchers, and students to explore data-driven insights without rigid assumptions, as seen in applications like portfolio optimization and macro forecasting.
All of the material including presentation, slides and an AI overview of the NNS package can be accessed here. Also, all of the apps have introductory versions where users can get accustomed to the format and output for macroeconomic forecasting, options pricing and portfolio construction via our main page.
If you're curious to learn more about Fred’s fascinating work on Partial Moments Theory & its applications, Fred's created a LinkedIn group where he shares technical insights and ongoing discussions. Feel free to join here.
Numbers & Narratives
Drawdown Gravity: Base-Rate Lessons from 6,500 U.S. Stocks
Morgan Stanley just released a sweeping analysis of 40 years of U.S. equity drawdowns, tracking over 6,500 names across their full boom–bust–recovery arcs. The topline stat is brutal: the median maximum drawdown is –85%, and more than half of all stocks never reclaim their prior high. Even the top performers, those with the best total shareholder returns, endured drawdowns >–70% along the way.
Their recovery table is where it gets even more interesting. Past a –75% drop, the odds of ever getting back to par fall off sharply. Breach –90% and you're down to coin-flip territory. Below –95%, just 1 in 6 names ever recover, and the average time to breakeven stretches to 8 years. Rebounds can be violent, sure, but they rarely retrace the full path. Deep drawdowns mechanically produce large % bounces, but they do not imply true recovery.
What this means for quants:
Tail-aware position sizing: If your models cap downside at –50%, you're underestimating exposure. Add tail priors beyond –75%, where the drawdown distribution changes shape sharply.
Drawdown gating for signals: Post-collapse reversal signals (value, momentum, etc.) need contextual features. Look for signs of business inflection, such as FCF turning, insider buys, or spread compression.
Hold cost assumptions: In the deep buckets, time-to-par often exceeds 5 years. That has material implications for borrow cost, capital lockup, and short-side carry in low-liquidity names.
Feature engineering: Treat drawdown depth as a modifier. A 5Y CAGR post –50% drawdown is not the same as post –90%. The conditional distribution is fat-tailed and regime-shifting.
Scenario stress tests: Do not assume mean reversion. Model drawdown breakpoints explicitly. Once a name breaches –80%, median recovery trajectories flatten fast.
Portfolio heuristics: If your weighting relies on mean reversion or volatility compression, consider overlaying recovery probabilities to avoid structural losers that only look optically cheap.
The data challenges the assumption that all drawdowns are temporary. In many cases, they reflect permanent changes in return expectations, business quality, or capital efficiency. Quants who treat large drawdowns as structural breaks rather than noise will be better equipped to size risk, gate signals, and allocate capital with more precision.

Link to the report
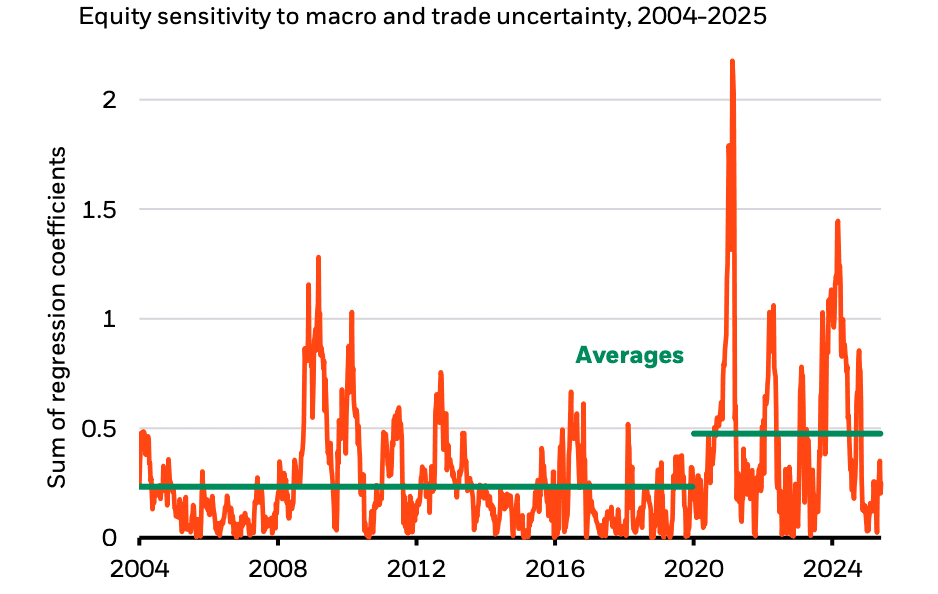
Market Pulse
Hedge funds posted strong gains in May, with systematic equity strategies up 4.2%, lifted by the sharp reversal in tech and AI-linked stocks following a de-escalation of tariff threats. Goldman Sachs noted the fastest pace of hedge fund equity buying since November 2024, concentrated in semiconductors and AI infrastructure, but this flow was unusually one-sided - suggesting not conviction, but positioning risk if the macro regime turns. That fragility is precisely what firms like Picton Mahoney are positioning against; they’ve been buying volatility outright, arguing that the tariff “pause” is superficial and that policy risk remains deeply underpriced. Steve Diggle, too, sees echoes of 2008, pointing not to housing this time, but to opaque leverage in private credit and structurally overvalued equity markets, especially in the U.S., where he warns few investors are properly hedged. That concern is echoed institutionally: the Fed stayed on hold warning that persistent fiscal imbalances and rising Treasury yields could weaken the foundations of the U.S.'s safe-haven role over time, a risk amplified by Moody’s recent downgrade of U.S. sovereign credit from AAA to AA1. While equities soared, the rally was narrow, factor spreads widened, and dispersion surged leaving a market primed for relative value, long-volatility, and cross-asset macro strategies. Taken together, this is a market that rewards tactical aggression but punishes complacency—an environment where quant managers must read not just the signals, but the mispricings in how others are reacting to them.
Navigational Nudges
Cross-validation that ignores the structure of financial data rarely produces models that hold up in live trading. Autocorrelation, overlapping labels, and regime shifts make naïve splits risky by design. In practice, most overfitting in quant strategies originates not in the model architecture, but in the way it was validated.
Here’s how to choose a split that actually simulates out-of-sample performance:
Walk Forward with Gap
Useful for: Short-half-life alphas and data sets with long history.
Train on observations up to time T, skip a gap at least as long as the label horizon (rule of thumb: gap ≥ horizon, often 1 to 2 times the look ahead window), test on (T + g, T + g + Δ], then roll. Always use full trading days or months, never partial periods.
Purged k-Fold with Embargo (López de Prado 2018)
Useful for: Limited history or overlapping labels in either time or cross section.
Purge any training row whose outcome window intersects the test fold, then place an embargo immediately after the test block. Apply the purge across assets that share the same timestamp to stop cross sectional leakage. If data are scarce, switch to a blocked or stationary bootstrap to keep dependence intact.
Combinatorial Purged CV (CPCV)
Useful for: Final-stage robustness checks on high-stakes strategies.
Evaluate every viable train-test split under the same purging rules, then measure overfitting with the Probability of Backtest Overfitting (PBO) and the Deflated Sharpe. Combinations scale roughly as O(n²); budget compute or down-sample folds before running the full grid.
Nested Time-Series CV
Useful for: Hyper-parameter-hungry models such as boosted trees or deep nets.
Wrap tuning inside an inner walk-forward loop and measure generalisation on an outer holdout. Keep every step of preprocessing, including feature scaling, inside the loop to avoid look ahead bias.
Pick the simplest scheme that respects causality, then pressure test it with a stricter one. The market will always exploit the fold you didn’t test, and most models don’t fail because the signal was absent, they fail because the wrong validation was trusted. Nail that part and everything else gets a lot easier.
The Knowledge Buffet
🎙️ Trading Insights: All About Alternative Data🎙️
by JP Morgan’s Making Sense
In this episode, Mark Flemming-Williams, Head of Data Sourcing at CFM and guest on the podcast, offers one of the most refreshingly honest accounts we've heard of what it really takes to get alternative data into production at a quant fund. From point in time structure to the true cost of trialing, it’s a sharp reminder of how tough the process is and a great validation of why we do what we do at Quanted. Well worth a listen.
The Closing Bell

——
Disclaimer, this newsletter is for educational purposes only and does not constitute financial advice. Any trading strategy discussed is hypothetical, and past performance is not indicative of future results. Before making any investment decisions, please conduct thorough research and consult with a qualified financial professional. Remember, all investments carry risk